Machine Learning for Fraud and Anomaly Detection
We develop specific machine learning methods for the special topic of fraud and anomaly detection. A particularity of this topic is to deal with highly unbalanced datasets in a context where fraudsters strategies evolve over time. Our work targets applications in bank fraud detection and anomaly detection in medicine and accident prevention.

Anomaly detection is a key problem in many varied and challenging domains with high societal or industrial impacts such as fraud detection, intrusion detection, video-surveillance, fault detection or healthcare. These applications share a common issue: learning data are generally highly unbalanced due to the difficulty to get a sufficient amount of instances characterizing an anomaly or a fraud. In this context, we propose to work on new machine learning methods and frameworks to address this problem. Our approach relies on our skills in metric/representation learning, transfer learning and data mining.
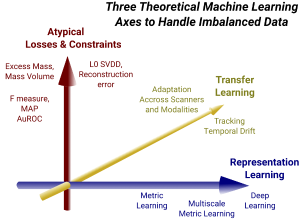
In this context, our research interests include:
-Local and contextual representation learning. Representation learning such as metric learning and deep learning has a great impact on many domains and applications. In the challenging context of highly imbalanced data, a global model is often insufficient: it is necessary to have precise local models and combine them accordingly to take into account contextual information. In some applications such as in fraud detection, being able to design relevant representations for detecting unexpected events is particularly challenging since for example fraudulent behaviors tend to look similar to normal ones.
-Transfer learning for dealing with fraud and system evolutions. In the context of fraud detection, to prevent the systems from catching them, fraudsters make their strategies evolve over time. We propose to address this issue by considering online transfer learning methods from highly unbalanced data. In other application areas, such as medical imaging, transfer is required to deal with different sources and modalities of acquisition used for each patient. Here, our objective is to develop transfer learning methods for making use of all these multi-modal/multi-source informations.
-Design of new specific machine learning frameworks with atypical losses. Classic machine learning losses that optimize classification accuracy fail in the context of highly unbalanced data. Alternatives consist to use other functions such as the F-measure or the area under ROC curve. However, these alternatives are not sufficient when the data imbalancy is extreme and when some additional constraints must be considered (budget, privacy, ...).
-Applications related to bank fraud dection and outlier detection in medical imaging. We focus particularly on the detection of brank frauds in the context of partnerships with companies working in the transactional services industry. We are also interested in medical applications related to the detection of anomalies in medical images.
Note that our focus is not restricted to the applications mentioned above, we are open to other applications areas. Please do not hesitate to contact us in case of interest.
| previous topic: Transfer Learning and Domain Adaptation | next topic: Machine Learning for Computer Vision Applications |