Social and Personalized Information Retrieval
The quantity of information available on the Web (concept of Big Data) and the presence of dynamic web data requires fine tuned information retrieval systems to propose relevant documents to a specific user query. However, it is generally difficult for classic systems to index efficiently all the web and their answers are not specific enough to user needs. We propose to investigate Social and Personalized Information Retrieval to tackle these drawbacks.
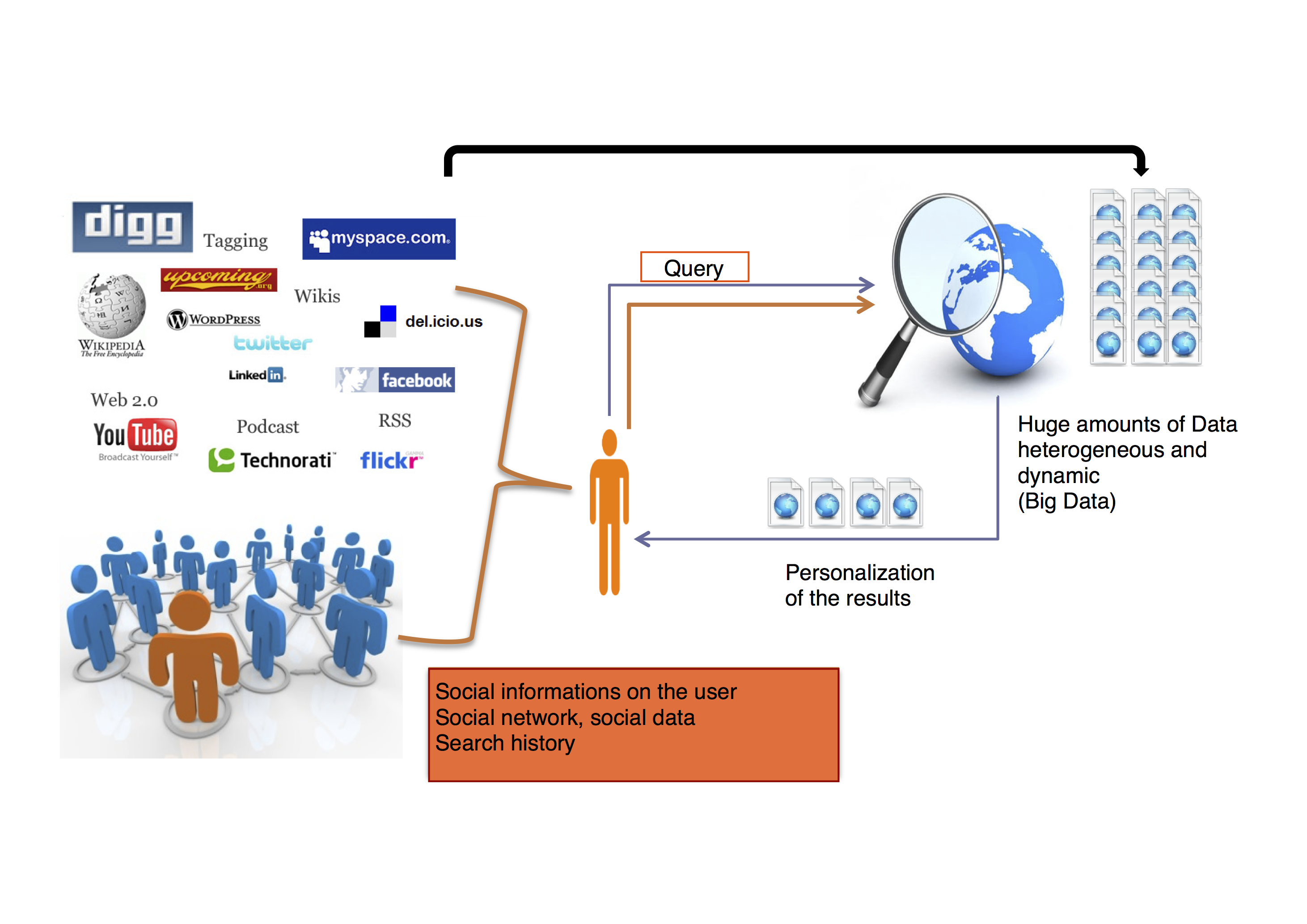
Nowadays, with Big Data and the huge, heterogeneous and dynamic Web data available, information access relies mainly on general search engines. These engines are document-centered and as a consequence hide generally a part of the web due to a lack of adaptation to specific user needs or to a lack of indexing coverage. In this context, we propose to work on Social and Personalized Information Retrieval (SPIR), which aims to customize the information access for specific users and to provide access to the hidden Web.
More specifically, we propose to address the following issues:
-How to model social information from heterogeneous sources and how to make use of them for SPIR? A SPIR system needs to take advantage of multiple "sources of evidence" of different nature (text, annotations, recommandations, notes, popularity, score of a document for a given query) that may relate to both documents and users. Then, a SPIR model requires (i) to be able to integrate these different types of social information in a unified formalism and (ii) to be able to make use of these sources jointly which requires the development of more complex combination methods than classic linear combinations of scores.
-How to personalize SPIR? Classic information retrieval models where the relevance of a document for a given query is estimated thanks to a correspondance function between query and documents. We propose to take into account the target user in the model of social information retrieval by personalizing the modeling of the information thanks to a subjective indexing model or in other words to develop a SPIR model allowing each user to have its own distributed and personalized index adapted to its needs. Building this index requires to integrate diverse social informations enriching the description both of the information need and of the documents.
-How to take advantage of the social network of the user for SPIR? The social network of a user, or its social neighboring - the set of all users connected to him - is a particularly important source of social information. We think that this kind of information can play a crucial role for personalizing information retrieval. To make use of such an information we need to model not only the user but also the context of its direct social information and its social neighboring in the context of its indirect social informations.
This topic is also adressed in the Data Mining for Complex Data theme.
| previous topic: Data Mining for Image and Video Analysis |