Article: Proposal-Contrastive Pretraining for Object Detection from Fewer Data

As part of the 11th ICLR 2023 held this year in Kigali, Rwanda, our Data Intelligence team presented their latest work on unsupervised contrastive representation learning for frugal object detection. The article was ranked amongst the top 25% of the papers presented at the conference.
In this work, we consider the problem of object detection where the goal is to predict the localization and class of each instance of objects in an image. We present Proposal Selection Contrast (ProSeCo), an unsupervised pretraining method for transformer-based detectors using a fixed pretrained backbone. Our approach helps achieving better performance when fine-tuning the model with fewer training data afterwards. ProSeCo makes use of two copies of the detection model following a student-teacher framework. The aim is to alleviate the discrepancy between features used for pretraining by maintaining copies of the whole detection model. The first one is referred to as the teacher model in charge of the object proposals embeddings, and is updated through an Exponential Moving Average (EMA) of the second copy, the student model, making the object predictions. This latter network is trained by a contrastive learning approach leveraging the high number of object embeddings that can be obtained from the detectors. The idea is to move closer pairs of embeddings of sufficiently similar predictions for a same object in the image (positive pairs), while pushing away pairs of embeddings of different objects (negative pairs). Working directly with the large number of object embeddings obtained by transformer-based detectors, in addition to the absence of batch normalization in the architectures, reduces the need for a large batch size. We further adapt the contrastive loss commonly used in pretraining to take into account the locations of the object proposals in the image, which is crucial in object detection. In addition, the localization task is independently learned through a separate regularization task using region proposals generated by the Selective Search algorithm.

Figure 1 below: Overview of our ProSeCo method. The "coord" and "giou" losses measure the adequation between the localization of the boxes; the LocSCE loss corresponds to the contrastive loss proposed in the paper.
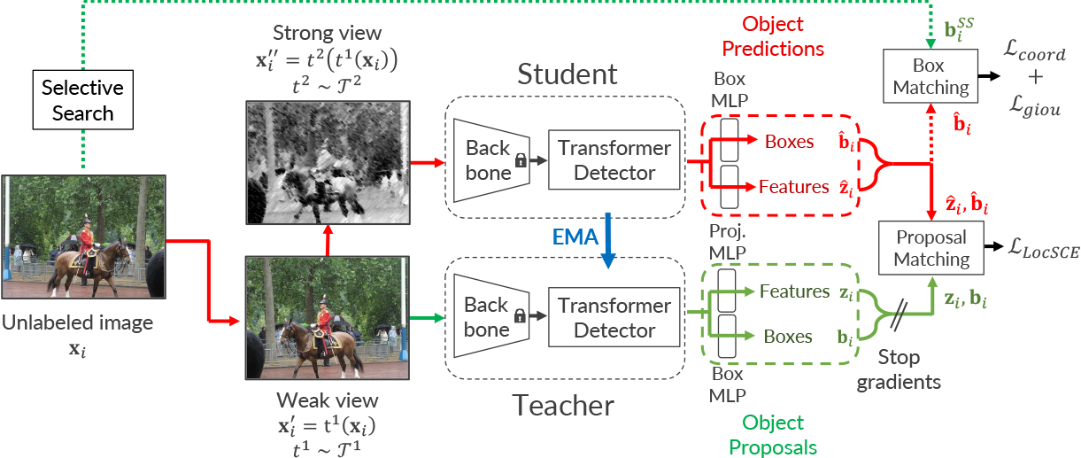
Figure 2 below: Our neural network (green box) takes several images as input (yellow) in addition to half of the information of the reference image (blue). It produces a restored image (blue image on the right) that can be compared to the other half of the reference image (red). This guides the training of the network.
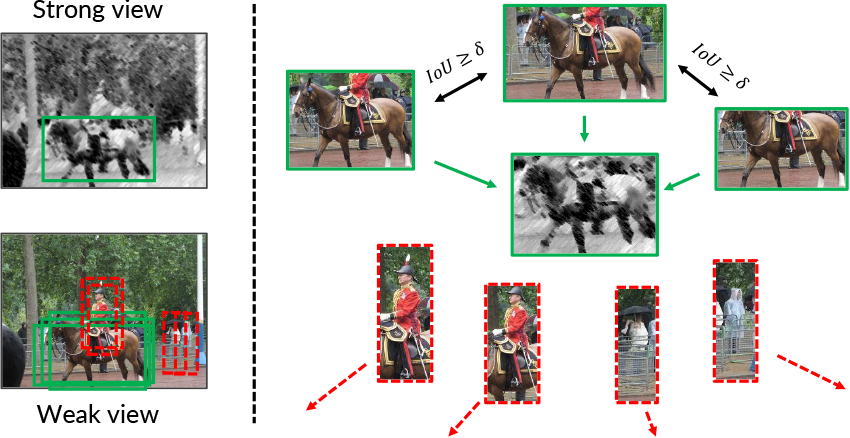
Figure 3 below: Definition of the LocSCE loss that introduces the localization of objects.
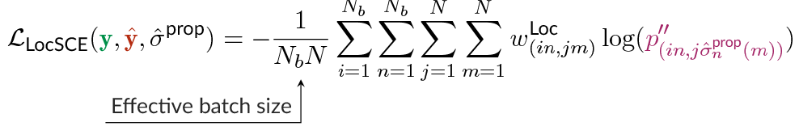
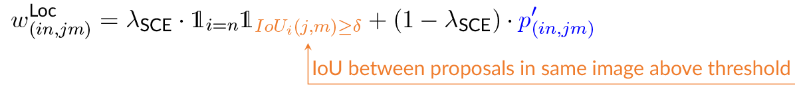

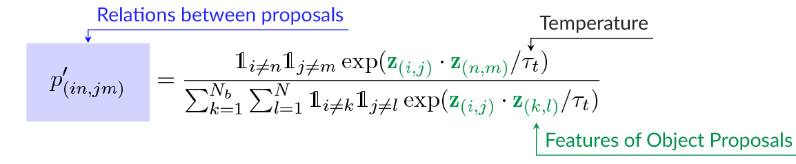
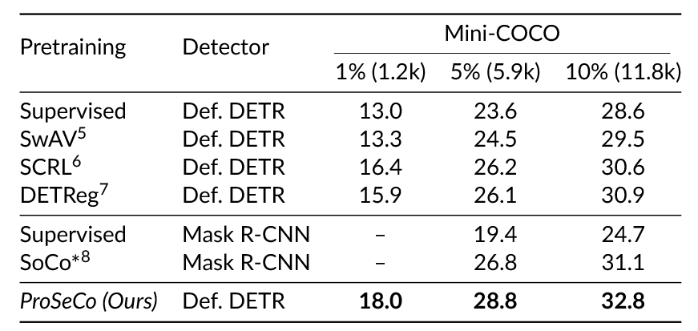
Table 1 below: Performance (mAP in %) when finetuning the pretrained models on the Mini-COCO benchmark.
Abstract
The use of pretrained deep neural networks represents an attractive way to achieve strong results with few data available. When specialized in dense problems such as object detection, learning local rather than global information in images has proven to be more efficient. However, for unsupervised pretraining, the popular contrastive learning requires a large batch size and, therefore, a lot of resources. To address this problem, we are interested in transformer-based object detectors that have recently gained traction in the community with good performance and with the particularity of generating many diverse object proposals. In this work, we present Proposal Selection Contrast (ProSeCo), a novel unsupervised overall pretraining approach that leverages this property. ProSeCo uses the large number of object proposals generated by the detector for contrastive learning, which allows the use of a smaller batch size, combined with object-level features to learn local information in the images. To improve the effectiveness of the contrastive loss, we introduce the object location information in the selection of positive examples to take into account multiple overlapping object proposals. When reusing pretrained backbone, we advocate for consistency in learning local information between the backbone and the detection head. We show that our method outperforms state of the art in unsupervised pretraining for object detection on standard and novel benchmarks in learning with fewer data.
Read the full article here