Metric and Representation Learning
The objective of representation and metric learning is to build new spaces of representations to improve the performance of a classification, regression or clustering algorithm either from distance constraints or by making use of fine decomposition of instances in complete samples. We address this topic both from a theoretical standpoint and a practical one by providing new methods and algorithms in metric learning or deep learning.
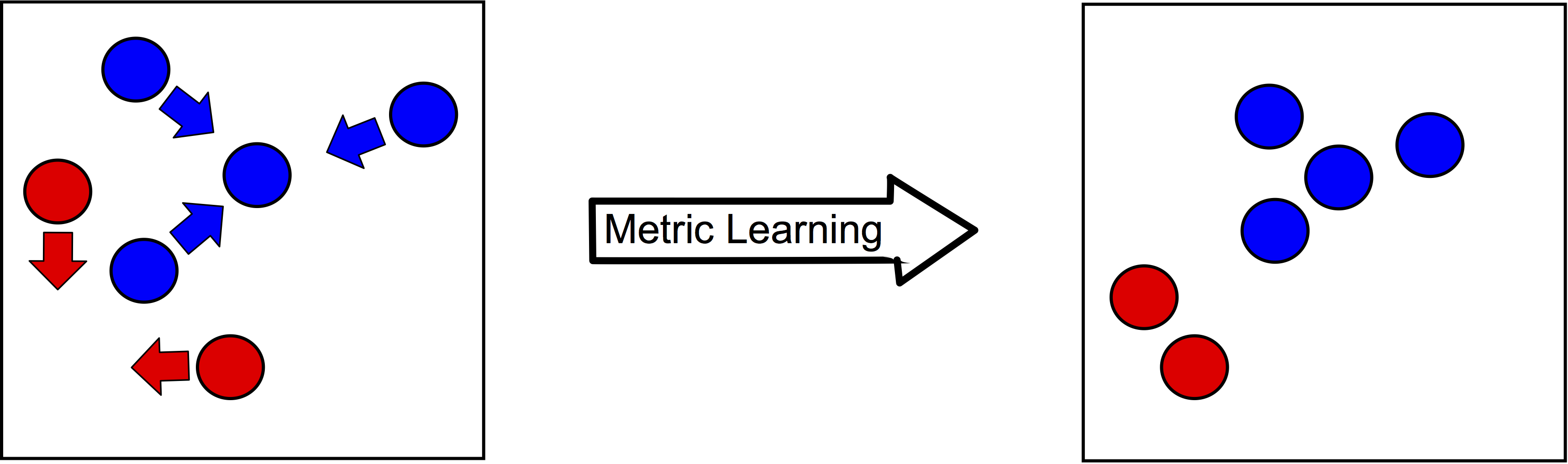
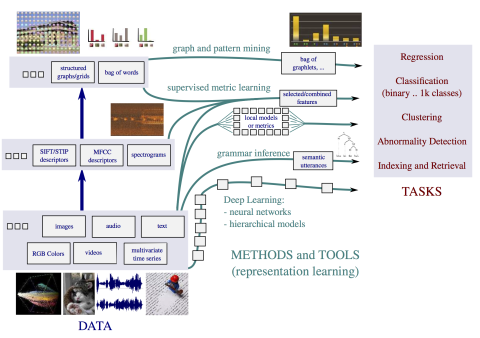
Many machine learning or data mining methods require an accurate representation of the data to build efficient classification, regression or clustering models. As a consequence, representation learning is a key element of any machine learning/data mining system nowadays. We address the issue of representation learning according to two main directions: (i) explicit representation learning with deep learning methods, (ii) implicit representation learning with metric learning-based approaches when the representation is built thanks to pairwise (or triplet) constraints. In most of contributions we aim at providing new algorithmic methods with strong theoretical guarantees.
Our research interests include:
-Development of new deep learning architectures. We work on the definition of new archictectures able to take into account some specific constraints along the different layers to control the type of representation learned.
-Derivation of generalization guarantees. We try to provide strong theoretical frameworks to derive some consistency guarantees for methods trying to find a better transformation of the original data. We obtained so far many results for metric learning methods from labeled samples and we plan to extend those results to more general representation learning settings. Additionally, we are also interested in deriving generalization guarantees for classifiers making use of learned metrics or representations.
-Development of new representation/metric learning in different contexts and for various tasks. Here we are interested in developping new (algorithmic) solutions for representation learning in particular settings such as transfer learning/domain adaptation or in the context of highly unbalanced data for fraud or anomaly detection, or more generally for classification, regression or clustering tasks. This topic is related to the other themes developped in the team.
Next research and project topic >